
Why Kubernetes is not part of our stack
By Drew Rothstein, Director of Engineering

TLDR: Container orchestration platforms are complex and amazing technologies, helping some businesses and teams solve a whole suite of problems. What’s commonly overlooked however, is that container technologies also create a large set of challenges that must be overcome to prevent failures.
This post is adapted from an internal blog post as I haven’t seen many write-ups like this externally available. Minimal redaction has been done and images have been added to provide more flare. If you are interested in working on some of what we discuss below — we are actively hiring on our Infrastructure team.
History
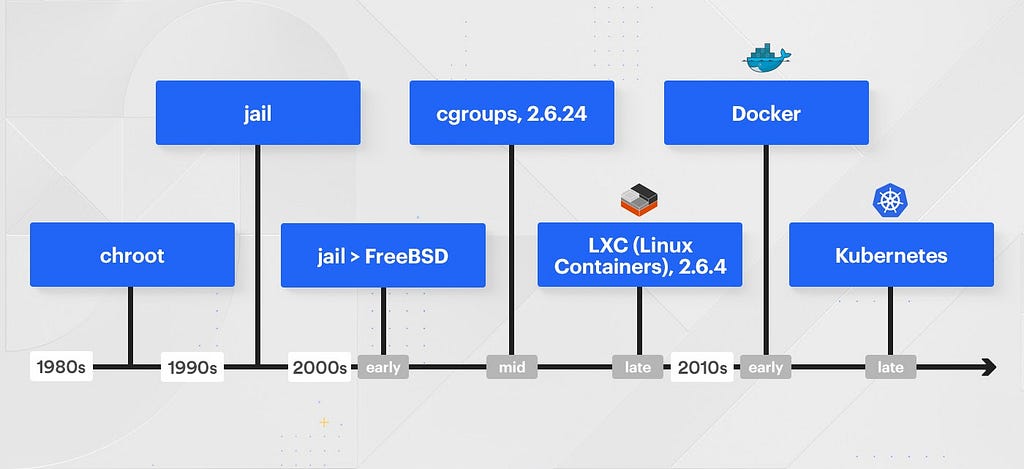
Before jumping into the current day, it is important to understand the technologies that led us here.
- 1980s: chroot
- 1990s: jail
- 2000s (early): jail > FreeBSD
- 2000s (mid): cgroups, 2.6.24
- 2000s (late): LXC (Linux Containers), 2.6.4
- 2010s (early): Docker
- 2010s (late): Kubernetes
There is a more detailed history in Chapter 7 of Enterprise Docker if interested.
Without containers as we know them today, let’s go back ~10yrs. At this time we did not have/use docker, rkt, or any other mainstream containerized wrapper/service. Most large-scale companies built in-house systems to bundle their applications to go from source code to deployment in production. What engineers ran on their machine was usually not what was running in production or if it was, it was lovingly one-off built/packaged in a manner that was likely very custom and complex.
In this world of an in-house system to bundle and deploy applications there was a large operations team, usually in a platform or infrastructure organization that would manage the bundle/building processes, deployment, and post-deployment. These roles were generally highly operational involving troubleshooting bad hosts, diagnosing specific dependency issues on OS patches/upgrades, etc. Post-deployment had minimal to no automated orchestration and involved capacity planning, ordering more servers, getting them racked/installed, and somehow getting software updated on them.
If you were lucky, there was some regular process to build a “golden image” (think: Packer by Hashicorp) that was well documented, potentially even codified, and run by a Continuous Integration system such as Hudson (previous to Jenkins {ref}). These images were somehow distributed to your systems either manually or automatically through some sort-of configuration management utilities and then started in some ordering, likely with parallel SSH or similar.
This past decade everything has changed. We went from gigantic monolithic applications to breaking down services into more discrete and less coupled parts. We went from having to build/own your own compute to having a managed or Public Cloud offering with a couple clicks and a credit card. We went from scaling applications vertically to re-architecting them to scale horizontally. All of this was happening at the same time that societal changes were also occurring: cell phones in every pocket, network speeds improving, network latencies dropping across the world, to doing everything online from booking your dog walker to commoditized video conferencing.
AWS’s offering in 2009 was quite limited. For perspective, it wasn’t until 2008 when AWS’s EC2 offering exited beta and began offering an SLA (ref). For reference, GCP didn’t launch a compute offering in GA until 2013 (ref).
Why do companies choose to containerize their applications?
Companies choose to containerize their applications to increase engineering output/developer productivity in a quick, safe, and reliable manner. Containerizing is a choice made vs. building images, although containers can sometimes be built into images, but that is out of scope (ref).
Containers enable engineers to develop, test, and run their applications locally in the same or similar manner that they will run in other environments (staging and production). Containers enable bundling of dependencies to be articulated and explicit vs. implied (the OS will always contain package $foo that my service depends on). Containers allow for more discreet service encapsulation and resource definition (using X CPUs and Y GB of Memory). Containers inherently enable you to think about scaling your application horizontally vs. vertically, resulting in more robust architectural decisions.
Some of these points could be argued in great detail. These are purposely bold and a bit over-extended to move the conversation forward as this isn’t a discussion of the pros/cons of containerization or service-ification (i.e. the breakdown of monolithic applications to a proliferation of more discreet services that run separately).
What about virtualization?
Virtualization is the concept of being able to run multiple containers on an OS virtualized system (ref). Containers can only see the devices/resources granted to it. On a managed compute platform such as AWS you are actually running below a Hypervisor (ref) which manages the VMs that your OS and resulting containers run within.
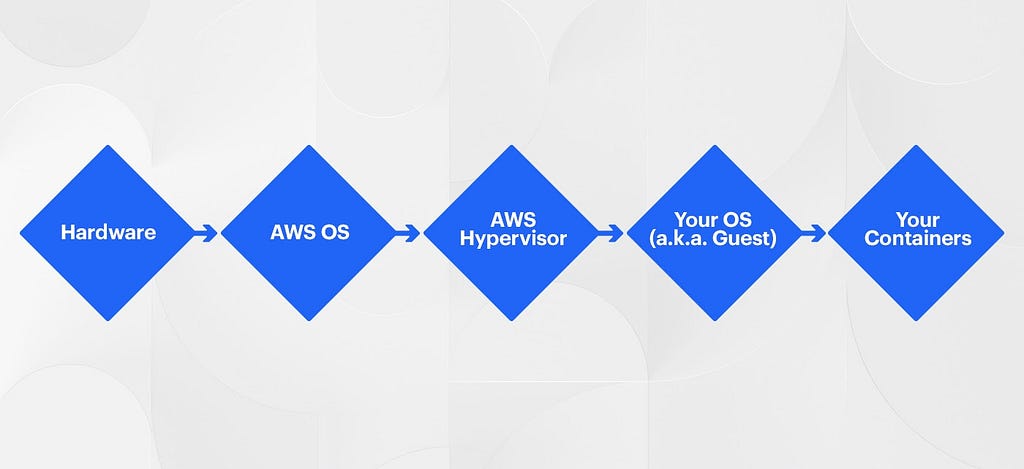
Virtualization enables the world of containers today. Without the ability to virtualize, hardware resources running multiple applications in containers wouldn’t be possible today.
What problem does a container orchestration platform (Mesos, Kubernetes, Docker Swarm) solve?
A container orchestration platform solves the following types of problems:
- Managed/Standardized deployment tooling (deployment).
- Scaling of applications based-on some defined heuristic (horizontal scaling).
- Re-scheduling/Moving containers when failures occur (self-healing).
While some platforms may state that they have other features such as storage orchestration, secret/config. management, and automatic bin packing to name a few: the reality is that these generally do not work for larger scale installations without intense investments either in forking / customization or through integrations and separation.
For example, most folks that run large-scale container orchestration platforms cannot utilize their built-in secret or configuration management. These primitives are generally not meant, designed, or built for hundreds of engineers on tens of teams and generally do not include the necessary controls to be able to sanely manage, own, and operate their applications. It is extremely common for folks to separate their secret and config. management to a system that has stronger guarantees and controls (not to mention scaling).
Similarly for service discovery and load balancing it is quite common to separate this out and run an overlay or abstract control plane. It is quite common to deploy Istio to handle this for Kubernetes. Managing and running Istio is not a trivial task and many modern-day cluster outages are due to misconfiguration of this control plane/service mesh and a lack of understanding of the minute details of it.
What do we use as our container orchestration platform?
Our container orchestration platform is Odin + AWS ASGs (auto-scaling groups). When you click Deploy from Codeflow (our internal UI for deployments), Odin is invoked with an API call from Codeflow. Odin kicks off a step function and begins to deploy your application. New VMs are stood up in AWS and loaded into a new ASG, your software is fetched from various internal locations, a load balancer starts health-checking these new instances, and eventually traffic is cut over in a Blue/Green manner to the new hosts in the new ASG behind the load balancer.
Our container orchestration platform is extremely simple (on purpose). We enable the same key features of Kubernetes: A single Deploy + Rollback button in Codeflow, Scaling based-on some defined heuristic (we support custom AWS metrics or standard CPU metrics), and re-scheduling/moving of your containers if your VM dies/becomes unhealthy in your ASG.
To handle secrets and configuration management we have built a dynamic configuration service that provides libraries to all internal customers with a p95 of 6ms. It is backed by DynamoDB and serves 100s of thousands of requests per minute of synchronous and asynchronous methods types.
To handle service discovery and load balancing we utilize Route53 (DNS), ALBs (Application Load Balancers), and client-side load balancing for gRPC either natively or through Envoy. We expect to invest more here later in the year.
Why do we not run Kubernetes?
Running Kubernetes does not solve any customer (engineering) problems. Running Kubernetes would actually create a whole new set of problems.
- We would need to build/staff a full-time Compute team. While we may do this anyway as we grow, this would be required immediately so that they could focus on building out tens of clusters (likely separate for each team/org), starting to scope/build the wrapping/glue tooling, starting to build out the abstract control plane/service mesh, etc.
- Securing Kubernetes is not a trivial, easy, or well understood operation. To enable us to own/operate Kubernetes we would need the same tooling and controls that we have today with our entire platform (Odin, ASGs, Step Deployers — and everything they enforce). To build these same primitives providing the same level of safety that these provide today would be a substantial investment both by a (future) Compute team and our Security team.
- Managed Kubernetes (EKS on AWS, GKE on Google) is very much in its infancy and doesn’t solve most of the challenges with owning/operating Kubernetes (if anything it makes them more difficult at this time). At AWS they are scaling their support/operations teams to run EKS and at Google it isn’t uncommon for them to have multi-hour outages with GKE (ref). You are trading off some operations issues and challenges to another operations team (and removing a lot of visibility).
- Cluster upgrades and management require a much more operationally heavy focus than we have today. The only way to sanely run Kubernetes is by giving teams/orgs their own clusters (similar to giving them their own AWS accounts or GCP projects). Upgrading clusters and patching vulnerabilities is not a quick/easy task even with Istio and associated tooling. Generally you have to build/run a secondary cluster, failover all applications, and then fail back after an upgrade. This primitive is not built into any abstracts at this point in time. While this may exist for managed clusters (GKE) it doesn’t always work as you might expect and rolling back once started is generally not well handled.
- Today, we do not carry this burden. We run on a hardened OS with minimal > no dependencies. Our AMI rollout is managed starting with development and then moving forward after weeks of testing. If we need to rollback we have the ability to do so with a trivial one-line change. On average we spend < 5hrs/month on anything even closely related to this area of concern.
Additional references on the complexities of owning/operating Kubernetes & Istio:
- OpenStack (Kubernetes Issues At Scale 900 Minions)
- OpenAI (Scaling Kubernetes to 2,500 Nodes)
- Civis (Breaking Kubernetes: How We Broke and Fixed our K8s Cluster)
- k8s.af
Securing Kubernetes
Let’s discuss some of the complexity of securing and running Kubernetes as a business that stores more than $8 billion in crypto assets.
Components
The basics of securing a Kubernetes cluster (ref) are well known/understood but once you dig into each of them the complexities start to unravel. Securing all of the system components (etcd, kubelet), the API server, and any abstracts/overlays (Istio) opens up a lot of surface to understand, test, and secure. Going deep into namespaces, seccomp, SELinux, cgroups, etc. is all required given the increased attack surface. Kubernetes is so large that it has its own CIS benchmark & InSpec suite (thankfully).
Vulnerabilities
A small list of references that provide a good starting point for researching:
- CVE-2019–5736 (8.6 High): Allows attackers to overwrite the host runc binary (and consequently obtain host root access).
- CVE-2019–11246 (6.5 Medium): If the tar binary in the container is malicious, it could run any code and output unexpected, malicious results.
- CVE-2019–11253 (7.5 High): Allows authorized users to send malicious YAML or JSON payloads, causing the API server to consume excessive CPU or memory, potentially crashing and becoming unavailable.
Overview
Kubernetes is a powerful PaaS as a kit with lots of security-relevant options to support the variety of deployment scenarios that it can be used in. It’s incredibly valuable from a security perspective when it is the universal consensus choice for PaaS, because most of those options can be abstracted away, and secondary systems must be put into place to support its use.
Kubernetes is fundamentally designed for workload orchestration — Trust is not the differentiator or purpose behind the encapsulation or pieces in Kubernetes; The multi-tenancy purpose is for bin packing and not in support of furthering permission boundaries. It provides several layers at which you can choose to place mild boundaries of varying enforceability. Some of these boundaries are built-in, while others are simply integration points for other tools to help manage. Here are some of the primitives Kube provides (and doesn’t provide) to isolate workloads.
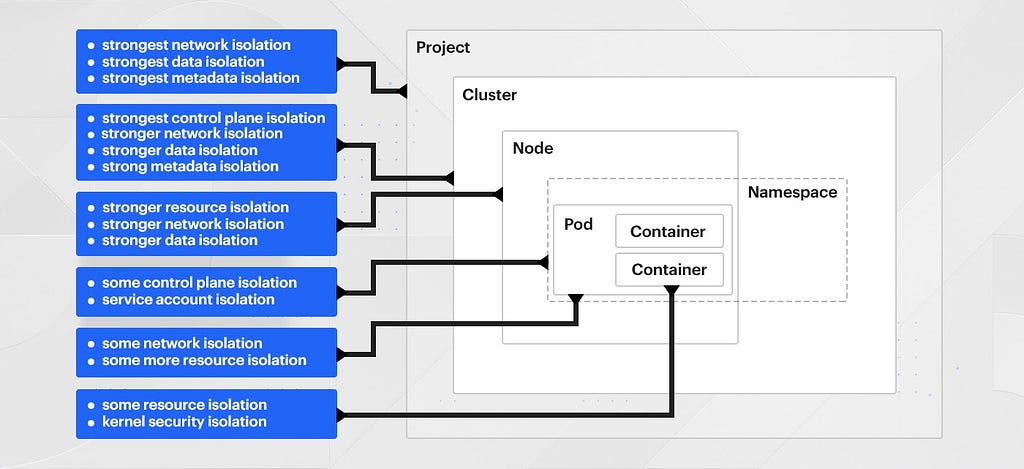
Control Plane (AWS Account / GCP Project)
Kubernetes clusters operate within the services and networks that are provided to them, and naturally have some interaction with the AWS/GCP control plane such as provisioning load balancers for ingress, accessing secrets stored in KMS, etc. Teams grow and expand to have separate accounts, projects, and further isolation over time. A separate AWS account or GCP project is the primary primitive by which you can achieve total IAM segmentation.
A Kubernetes cluster, on the other hand, needs to operate within one AWS account (even if federated with other clusters elsewhere). This limits segmentation options and flexibility. We could provision a cluster per team or service, but this takes away many of the efficiency gains that Kubernetes brings, and brings on new management problems, like meta-orchestrating all of those clusters.
Clusters & Nodes & Pods & Containers (Oh my!)
Clusters
Cluster master (API) servers are a secondary control plane (besides the AWS one) that we need to secure as well. Service accounts and access scopes, which containers can assume to access resources both within and outside the cluster, are just as complex as AWS’ IAM is, and need to be mapped against one another strictly so that a breakout does not affect the, e.g., AWS control plane.
Nodes
The operating system of the underlying nodes must be maintained much as we do today. In fact, our OS is very similar to the base OS Google uses for GKE. While we wouldn’t necessarily have to change anything to move our OS to Kubernetes, we wouldn’t gain anything either.
Pods
Creation of pods in the cluster, and the rules about what standards they have to meet to be created, are accomplished through PodSecurityPolicy, which operates similarly to Salus and our consensus management tooling today. We would have to invest in significant integration work, and additional open source dependencies, to cleanly integrate them.
Pods are segmented from each other through networking policies, much as we do today with Security Groups and/or our internal service framework. But in the world of Kubernetes, identity, authentication, and authorization of pods to communicate with each other involve a number of supporting technologies, such as SPIFFE and SPIRE for identity format and attestation below the node level, Envoy for authorization gating, Istio for authN and Z orchestration, and OPA for authorization policy. Each of these is a significant effort to standardize and adopt.
Containers
Containers are not security boundaries, they’re resource boundaries. In order to define security boundaries around containers, you need to delve into custom kernel namespaces, syscall filtering, mandatory access control frameworks, and/or vm-based isolation technologies designed for containers like gVisor.
Currently, we have not invested much in this area because we do not operate in a multi-tenant fashion. If we moved to a multi-tenant model, we would have to make significant investments here almost immediately so that we could trust that pods/containers are only running on the same nodes as similarly classified pods, and that they are not interfering with one another with host/vm isolation technologies.
When will we run Kubernetes and is Kubernetes in our future?
If/when there are significant use cases for a more advanced container orchestration platform we will likely first visit the problem statement. If this is something that can easily be added to our existing platform: we will likely visit that first and explore/scope from there. If we deem it unreasonable to extend/add to our platform then we would visit all potential options — not just Kubernetes. It is much more likely that we would visit AWS’s managed offerings first such as Fargate and ECS before diving in to Kubernetes based on the above.
If/when there are significant gains to be had by our engineers by offering Kubernetes (or any other container orchestration platform) we will explore offering them. At this time there is not a significant gain to be had by offering Kubernetes. This may change if/when Kubernetes offers enough new features that we haven’t kept up, they have paid down their technical debt (or we have not), or our customers require new functionality that they are able to offer and we are not in the foreseeable future. If the barrier to entry of our current platform were to significantly change and that were now a clear differentiator, then we would also explore offering a different platform.
If/when we hit the limits of our existing platform, are too deeply burdened or foresee being too deeply burdened in our platform due to missing features that our customers need, extending our platform is becoming too onerous, or we are having too many outages that are violating our SLA, than we would likely revisit a different container orchestration platform.
If/when we lose support of a major upstream dependency such as AWS or ASGs, we would then look into other options.
These are a few of the reasons we might choose to look into another container orchestration platform. At this time we have no plans to build/own/operate Kubernetes.
Doesn’t Kubernetes solve various problems such as re-balancing/auto-healing, auto-scaling, and service discovery? How do we solve these today?
Kubernetes at a smaller scale solves most of these problems without a lot of fuss. At a larger scale it requires a lot more thought, glue code, and putting wrappers / safe guards on pretty much everything to make it work safely and reliably. Generally, as mentioned above, folks tend to add a Service Mesh such as Istio to enable more advanced features / requirements.
Today we solve:
- Re-balancing/auto-healing with Odin and ASGs.
- Service discovery with DNS and Envoy.
Kubernetes has Storage Orchestration and we don’t have that today, should we?
We have two major stateful applications at Coinbase today- blockchain nodes and the trading engines that could be potential customers of a feature such as storage orchestration. For the former (blockchain nodes) the usage of storage is fairly custom and we have built a custom deployer that gives them the features that they need. For the latter (trading engines), we embedded from the Reliability (SRE) team and provided support to a number of their specific challenges.
While having Storage Orchestration built-in to Kubernetes might have been a nice starting point for both blockchain nodes and the trading engines- a lot of the same issues we have with the underlying technology would still exist.
What is the future of a Container Orchestration Platform if not Kubernetes?
We will explore and migrate to a higher-level abstracted service for some applications. We will explore Fargate and ECS as contenders for this purpose. The current initial reasons would be utilization and cost improvements — both of which are not very customer focused. We may choose to wait until we have more customer focused reasons to implement.
Potential customer focused asks would be around deployment times, deployment patterns (beyond canaries), more complex service mesh needs than exist today, or specific improvements/ features that may be added to Fargate or ECS that building onto existing tooling is not possible/not reasonable. These are some of the potential customer focused asks that are possible but not known or realized at this time.
Ideally the move to a different underlying container technology would be fairly invisible as the tools to interact with them wouldn’t fundamentally change. The reality of moving to a different platform would likely uncover hidden or unknown expectations about the existing system. How you deploy and debug services in staging and production would still be abstracted, but there may be different features offered that do not exist today.

Do I/we hate Kubernetes? Does Kubernetes fail as a container platform?
No. It is a great tool despite its challenges. Kubernetes has moved our industry forward in an increasingly positive direction. With Kubernetes well into a v1, the development of Knative, Fargate, and Cloud Run are increasingly raising the level of abstraction and solving the underlying challenges with managing Kubernetes. The future is bright. As these underlying challenges are solved, many existing concerns will likely be alleviated in the future.
If you are interested in working on our next generation of container technologies, our dynamic configuration service or other technologies mentioned above — we are actively hiring on our Infrastructure team. Please reach out and we would love to chat with you.
This website contains links to third-party websites or other content for information purposes only (“Third-Party Sites”). The Third-Party Sites are not under the control of Coinbase, Inc., and its affiliates (“Coinbase”), and Coinbase is not responsible for the content of any Third-Party Site, including without limitation any link contained in a Third-Party Site, or any changes or updates to a Third-Party Site. Coinbase is not responsible for webcasting or any other form of transmission received from any Third-Party Site. Coinbase is providing these links to you only as a convenience, and the inclusion of any link does not imply endorsement, approval or recommendation by Coinbase of the site or any association with its operators.
Unless otherwise noted, all images provided herein are by Coinbase.
Container technologies at Coinbase was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
The post appeared first on The Coinbase Blog





")